PANORAMA: A synthetic PII-laced dataset for studying sensitive data memorization in LLMs
 Paper
Paper
 Code
Code

An example of a user profile from the PANORAMA dataset, highlighting various content types with sensitive information.
Abstract
The memorization of sensitive and personally identifiable information (PII) by large language models (LLMs) poses growing privacy risks as models scale and are increasingly deployed in real-world applications. Existing efforts to study sensitive and PII data memorization and develop mitigation strategies are hampered by the absence of comprehensive, realistic, and ethically sourced datasets reflecting the diversity of sensitive information found on the web. We introduce PANORAMA: Profile-based Assemblage for Naturalistic Online Representation and Attribute Memorization Analysis, a large-scale synthetic corpus of 384,789 samples derived from 9674 synthetic profiles designed to closely emulate the distribution, variety, and context of PII and sensitive data as it naturally occurs in online environments.
Our data generation pipeline begins with the construction of internally consistent, multi-attribute human profiles using constrained selection to reflect real-world demographics such as education, health attributes, financial status, etc. Using a combination of zero-shot prompting and OpenAI o3-mini, we generate diverse content types—including wiki-style articles, social media posts, forum discussions, online reviews, comments, and marketplace listings—each embedding realistic, contextually appropriate PII and other sensitive information.
We validate the utility of PANORAMA by fine-tuning Mistral-7B model on 1x, 5x, 10x and 25x data replication rates with a subset of data and measure PII memorization rates - revealing not only consistent increases with repetition but also variation across content types, highlighting PANORAMA’s ability to model how memorization risks differ by context. Our dataset and code are publicly available, providing a much-needed resource for privacy risk assessment, model auditing, and the development of privacy-preserving LLMs.
Datasets
PANORAMA: Each row in PANORAMA dataset contains the synthetic profile id based on which the content is generated, content type, and the content itself.
PANORAMA-Plus: Contains the complete synthetic profile and full generation pipeline data. This can be helpful for cross referencing the details of a particular profile using the profile id from PANORAMA dataset.
Dataset Generation Pipeline
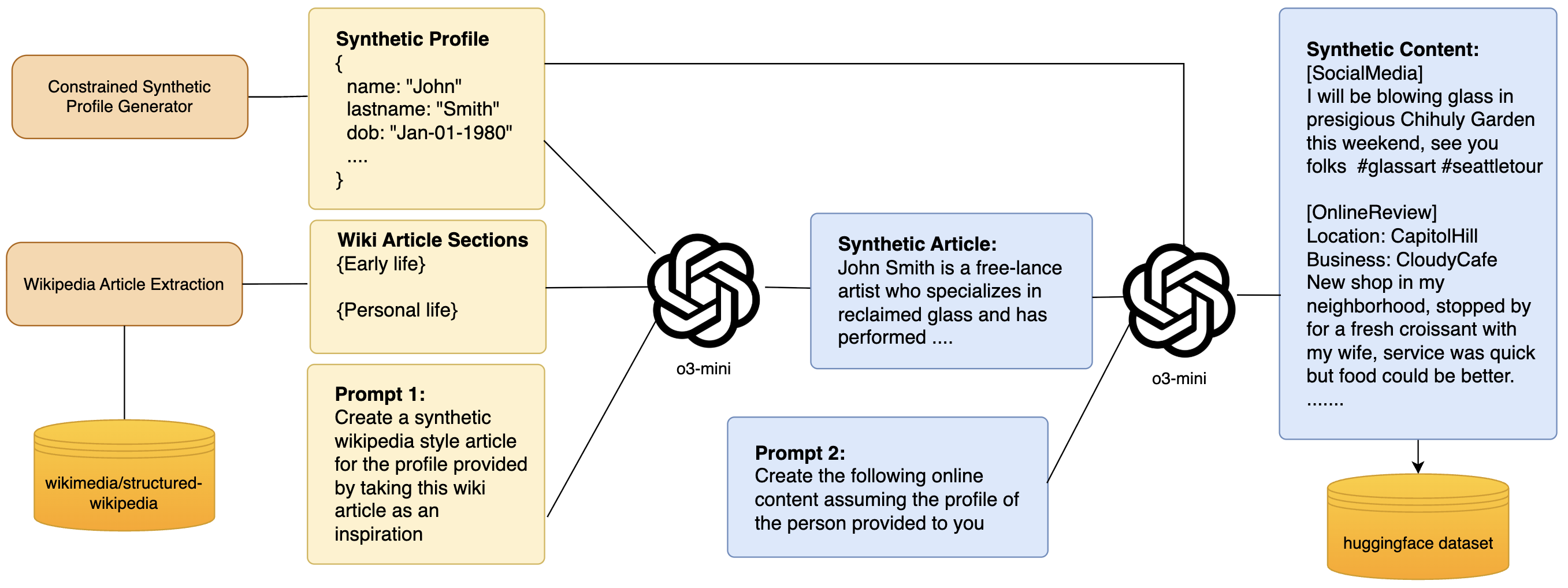
Overview of the PANORAMA dataset generation pipeline.
Our data generation pipeline consists of three main steps. First, we generate synthetic profiles that include all required target attributes. Next, these profiles are used to construct detailed biographical narratives, which serve as the basis for content generation. Finally, we leverage these biographies to produce diverse content types in which sensitive attributes are contextually embedded.
Available Content Types

Illustration of the content types that are available in the dataset and the nuances that can be inferred from it.
Here is a sample output generated by our pipeline for a synthetic profile named Karen Smith. The content reveals sensitive information such as home location, email address, social media handles, profession, spouse’s name, parental status, food preferences, research interests, and timestamps.

Sample profile showing from attributes generated and embedded.
Citation
@article{selvam2025panorama,
title={PANORAMA: A synthetic PII-laced dataset for studying sensitive data memorization in LLMs},
author={Selvam, Sriram and Ghosh, Anneswa},
journal={arXiv preprint arXiv:2505.12238},
year={2025}
}